June 29, 2026 · 7:26 AM
GLM-5.2 changes the model math
GLM-5.2 makes open-weight models credible enough for PMs to evaluate in coding, security, and agentic planning workflows. The brief explains why the real product move is model routing, not blanket model replacement, and gives a next-sprint evaluation path.

GLM-5.2 changes the AI vendor question from "Which frontier model is best?" to "Which model should handle this exact workload?"
Zhipu AI, now also branded as Z.ai, released GLM-5.2 to coding-plan members on June 13, 2026, then published open weights on Hugging Face under an MIT license on June 16. The model is a 744 billion-parameter Mixture-of-Experts system, meaning only about 40 billion parameters activate for each token instead of the whole model running on every request. 1 2 3
For product managers, the useful read is not "open weights beat closed labs." The useful read is narrower and more operational: GLM-5.2 looks strong enough on coding, security investigation, and agentic planning to deserve a place in your model router, but the evidence also says the harness, task type, and governance layer still decide whether it belongs in production.
What changed
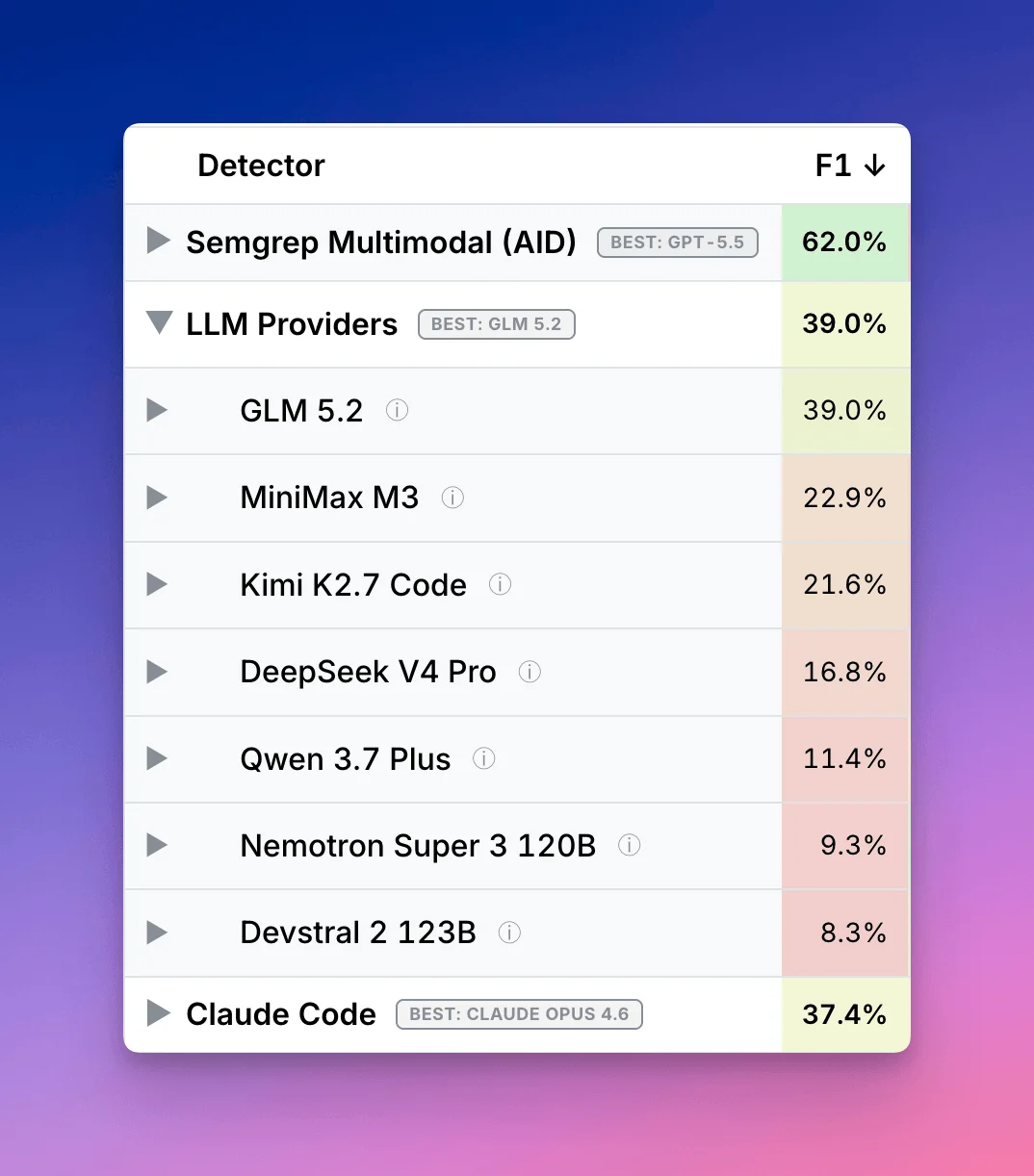
Semgrep tested GLM-5.2 on an IDOR vulnerability-detection benchmark using a minimal Pydantic AI harness and the same system prompt across models, with no endpoint discovery or guided navigation. GLM-5.2 scored 39% F1, ahead of Claude Code Opus 4.8/4.7 at 28% and Claude Code Opus 4.6 at 37%, and Semgrep estimated GLM-5.2 at about $0.17 per vulnerability found. 1
That is the headline, but the better PM signal sits one layer down. Semgrep's own multimodal pipeline scored 53-61% F1 on the same benchmark, above the prompt-only GLM-5.2 result. 1 The model matters, but the product wrapper still matters more.
Graphistry reported a similar pattern on CyBT-CTF, its agentic cybersecurity investigation benchmark. GLM-5.2 solved 28 of 59 tasks, tying Claude Opus 4.7/4.8, beating Claude Sonnet 4.5 at 23 of 59, and finishing well ahead of MiniMax 2.5 at 16 of 59. 4 Graphistry also reported that its Louie.ai harness with Opus reached 35 of 59, which again points to the same conclusion: model choice is one variable inside a larger system. 4
OpenRouter's June 2026 report ranked GLM-5.2 as the top open-weight model on the Artificial Analysis Intelligence Index v4.1 with a score of 51, ahead of Nemotron 3 Ultra at 48, MiniMax M3 at 44, DeepSeek V4 Pro at 44, and Kimi K2.6 at 43. 2 OpenRouter described GLM-5.2 as especially useful for architecture planning, repo-scale refactors, and long-running agent tasks. 2
The PM translation
The product move is to stop treating "frontier" as a single vendor tier. Treat models as workload-specific components.
| Product question | What GLM-5.2 changes |
|---|---|
| Can an open-weight model handle security or coding work that used to require a premium API? | Semgrep and Graphistry both found GLM-5.2 competitive with Claude variants on specific cybersecurity benchmarks, although both tests also show that harness design affects outcomes. 1 4 |
| Can the team get meaningful cost leverage? | Z.ai's first-party API price is reported at $1.40 per million input tokens and $4.40 per million output tokens, while OpenRouter reported a lower weighted-average price across providers of $0.447 per million input tokens and $3.31 per million output tokens. 5 2 |
| Can the team reduce API dependency risk? | The MIT license and open weights mean a team can evaluate hosted, private-cloud, or self-hosted paths, although full-precision self-hosting reportedly needs about 1.5 TB of GPU memory and quantized community builds are still around 239 GB. 3 |
| Can it replace multimodal frontier models? | No. OpenRouter lists GLM-5.2 as text-only, with no image or video input support. 2 |
This makes GLM-5.2 a practical candidate for model routing. A product team could send repo analysis, code repair drafts, security triage, or long planning tasks to GLM-5.2 while keeping vision, highly sensitive workflows, or tasks with weaker eval results on other models. The routing decision should come from the team's own eval set, not from a leaderboard average.
Where the trap is
The first trap is benchmark overreach. Semgrep's result is impressive, but it is still one IDOR benchmark under one prompt-only setup. 1 Graphistry's result is stronger external support, but it is still a cybersecurity investigation benchmark, not a universal product-quality guarantee. 4
The second trap is provenance and governance. Graphistry raised an unproven distillation concern after reporting Cohen's Kappa correlations of 0.80 between GLM-5.2 and GPT-5.5, 0.76 between GLM-5.2 and Opus 4.8, and 0.63 for the OpenAI-Anthropic baseline. 4 That is a claim to track, not a settled fact.
The third trap is security exposure. Axios reported that Russian-language forums discussed jailbreaks for GLM-5.2 within days of release and quoted Armadin founder Travis Lanham saying an attacker can run the model locally, fine-tune it against targets, and operate with no provider-visible signal. 6 For internal PM planning, the same property cuts both ways: local control can improve data sovereignty, but local control also removes provider-side abuse monitoring.
A product path for the next sprint
Start with a narrow eval, not a migration plan. Pick two or three workflows where model cost or latency is painful: repo-level code review, security triage, test generation, implementation planning, or long-document developer support. Use your own examples and compare GLM-5.2 against the current default model on answer quality, tool-use reliability, cost per completed task, latency, and failure mode.
Add routing before replacement. If GLM-5.2 wins on coding triage but loses on policy reasoning or multimodal input, the product architecture should route by task type rather than expose one model brand to users. OpenAI-compatible API support makes this easier across providers, and MarkTechPost reports support for reasoning-effort control, function calling, structured JSON, and streaming. 5
Keep governance in the scorecard. For each route, record hosting mode, data path, model provenance risk, output validation, and allowed task classes. A hosted Z.ai API, an OpenRouter route, a private deployment, and a local quantized build are different product-risk profiles even when they use the same model family.
The decision rule is simple: GLM-5.2 deserves a serious eval wherever your product has high-volume coding, security, or agentic planning workloads. It does not deserve a blanket replacement memo. The PM opportunity is to turn model selection into an explicit product surface before cost, access, or vendor policy forces the decision for you.
Cover image: image from Semgrep Security Research.
References
- 1We have Mythos at Home: GLM 5.2 beats Claude in our Cyber Benchmarks
- 2The Open Weight Models that Matter: June 2026
- 3AI Export Controls Fail Their First Real Test: GLM-5.2 Cybersecurity Benchmarks Expose the Gap
- 4GLM 5.2 Open Model: Beats Sonnet, Matches Opus in Cyber Evals
- 5GLM-5.2 OpenAI-Compatible API: A Hands-On Guide to Reasoning Effort, Function Calling, and Long-Context Retrieval
- 6China's new open-source model accelerates AI hacking threat
Add more perspectives or context around this Post.